Snowflake Destination
About this integration
Snowflake is a cloud data platform that provides a data warehouse-as-a-service designed for the cloud. It allows you to unify, integrate, analyze, and share previously siloed data.
How it works
This destination sends CSV, JSON, or parquet files containing your source data to an Amazon S3, Google Cloud Storage or Azure Cloud Storage bucket that you host. Then you can ingest the files in your storage bucket to your Snowflake data warehouse.
We write files for each type of source call to your storage bucket every 10 minutes. So you’ll have files for identify calls, track calls, and so on. Files are named with an incrementing number, so it’s easy to determine the sequence of files, and the order of calls made to your sources.
before next sync end
Sync frequency and file names
Syncs occur every 10 minutes. Each sync file contains data from the previous sync interval. For example, if the last sync occurred at 12:00 PM, the next sync will only send data from 12:00 PM to 12:09:59 PM.
Each sync generates new files for each data type in your storage bucket. Files are named in the format <destination id>.<subscription id>.<current position>.<type>.
- The Destination ID and Subscription ID are unique identifiers generated by Customer.io. You’ll see them with the first sync.
current positionis an incrementing number beginning at 1 that indicates the order of syncs. So your first sync is 1, the next one is 2, etc.typeis the type of source call—identify,track,page,screen,alias, orgroup.
So, if your file is called 2184.13699.1.track.json, it’s the first sync file for the track call type.
Getting started
To support Snowflake, you’ll set up a Google Cloud Storage, Amazon S3, or Microsoft Azure Blob Storage destination to store your data. Then, you’ll query and import data from your storage bucket to Snowflake either through a direct query or a product like Stitch.
As a part of this destination, we’ll create parquet, JSON, or CSV files in your storage bucket. See data warehouses for a list of data schemas.
Go to Destinations and click Add New.
Select the Snowflake destination.
Select the type of storage bucket you want to use, Google Cloud Storage (GCS), Amazon S3, or Azure Blob Storage.
Pick the sources you want to connect to your destination and click Next.
Connect your stoarge bucket. See instructions below for each storage bucket type.
Review your setup and click Finish to enable your destination.
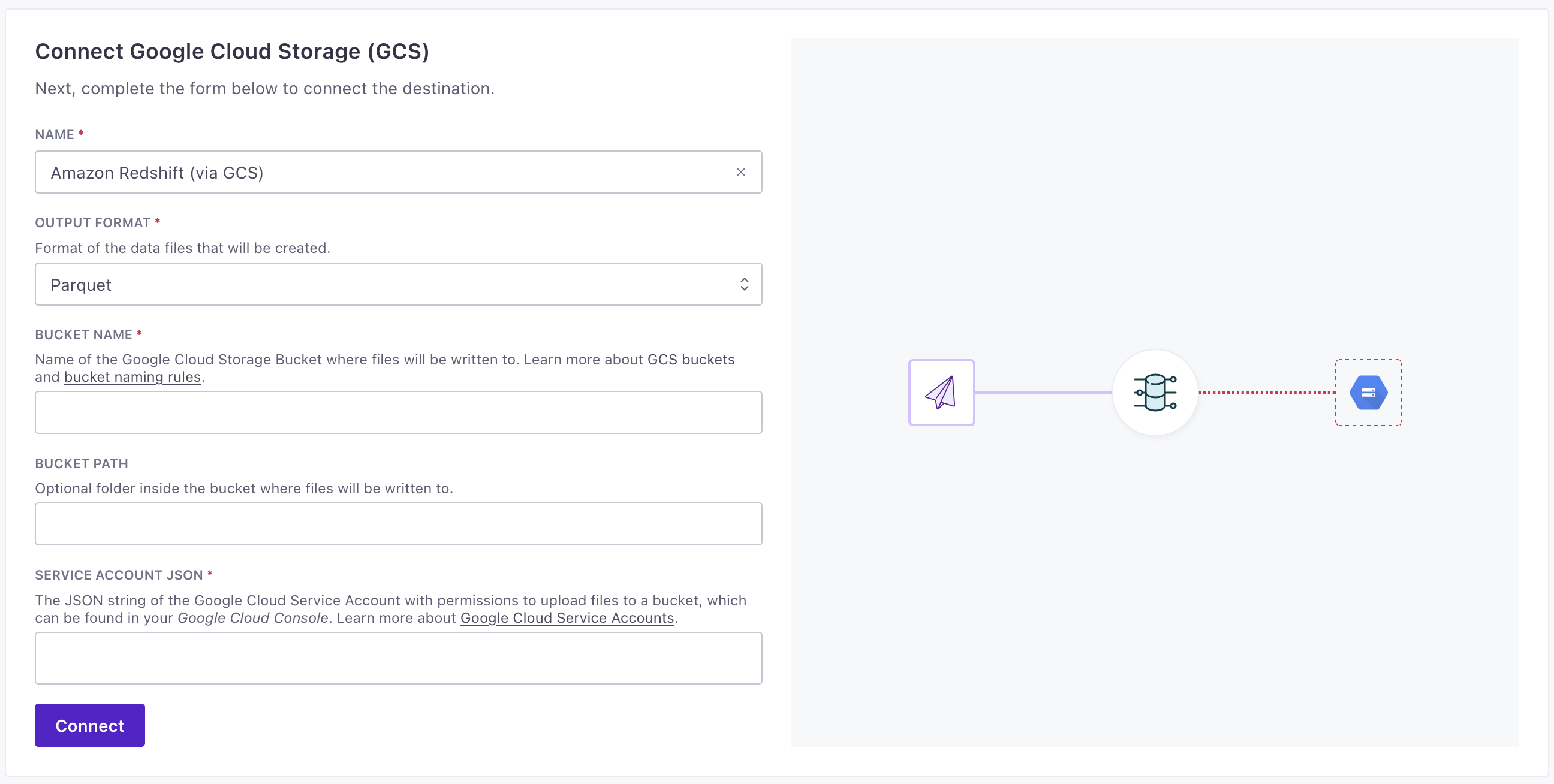
Google Cloud Storage (GCS)
Endpoint: Endpoint for the internal ETL API.
Token: Authentication token for the internal ETL API.
Format: Format of the data files that will be created.
Bucket Name: Name of the Google Cloud Storage Bucket where files will be written to. Learn more about GCS buckets and bucket naming rules.
Bucket Path: Optional folder inside the bucket where files will be written to.
Service Account: The JSON string of the Google Cloud Service Account with permissions to upload files to a bucket, which can be found in your Google Cloud Console. Learn more about Google Cloud Service Accounts.
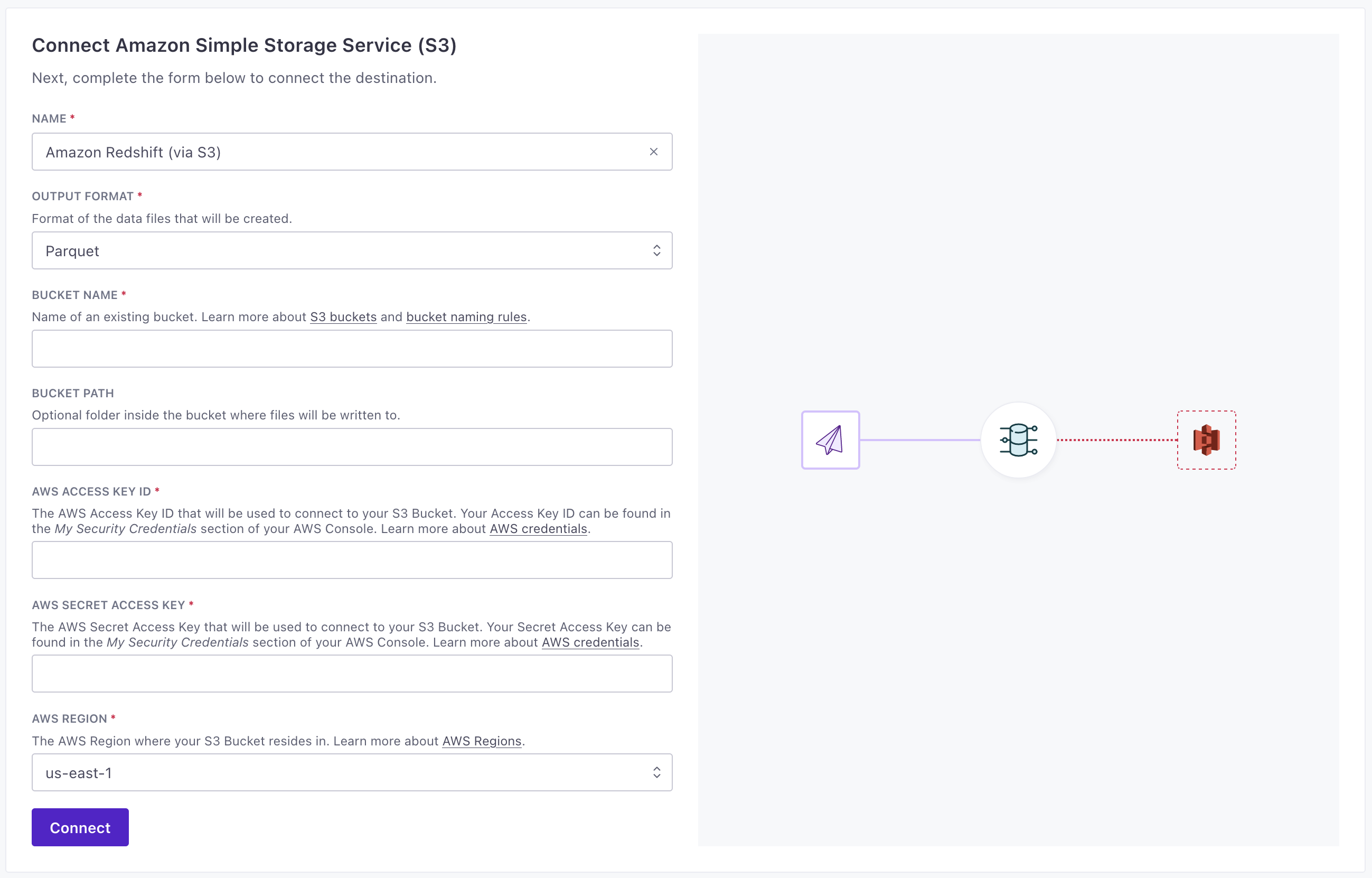
Amazon S3
Endpoint: Endpoint for the internal ETL API.
Token: Authentication token for the internal ETL API.
Format: Format of the data files that will be created.
Bucket Name: Name of an existing bucket. Learn more about S3 buckets and bucket naming rules.
Bucket Path: Optional folder inside the bucket where files will be written to.
Access Key: The AWS Access Key ID that will be used to connect to your S3 Bucket. Your Access Key ID can be found in the My Security Credentials section of your AWS Console. Learn more about AWS credentials.
Secret Key: The AWS Secret Access Key that will be used to connect to your S3 Bucket. Your Secret Access Key can be found in the My Security Credentials section of your AWS Console. Learn more about AWS credentials.
Region: The AWS Region where your S3 Bucket resides in. Learn more about AWS Regions.
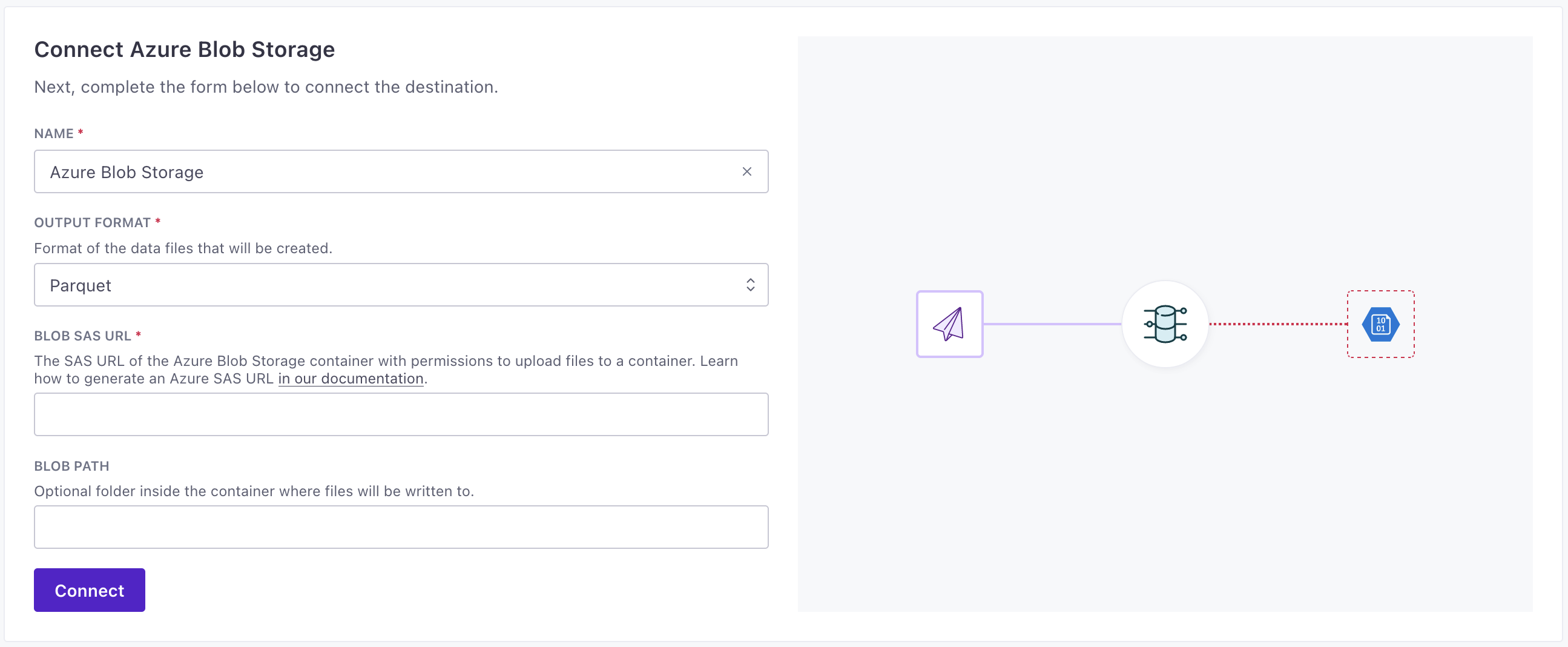
Azure Blob Storage
Endpoint: Endpoint for the internal ETL API.
Token: Authentication token for the internal ETL API.
Format: Format of the data files that will be created.
Blob Sas Url: The SAS URL of the Azure Blob Storage container with permissions to upload files to a container. Learn how to generate an Azure SAS URL in our documentation.
Blob Path: Optional folder inside the container where files will be written to.
Schemas
The following schemas represent JSON for the different types of files we export to your storage bucket (identify, track, and so on). For CSV and Parquet files, we stringify objects and arrays. For example, if identify calls contain the traits object with a first_name and last_name, CSV files output to your destination will contain a traits column with data that looks like this for each row: "{ "\first_name\": \"Bugs\", \"last_name\": \"Bunny\" }".
Identifies files contain identify calls made from your sources. The context and traits in the schema below are objects in JSON. In CSV and parquet files, these columns contain stringified objects.
- anonymous_id stringA unique substitute for a User ID in cases when you don’t have an absolutely unique identifier. Our libraries generate this value automatically to help you track people before they sign up, log in, provide their email, etc.
- contextA dictionary of context about a source call/event, like the user’s IP address or locale. Context is automatically collected by our source libraries.
- active boolean
Whether a user is active.
This is usually used to flag an .identify() call to just update the traits but not “last seen.”
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe local string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. Segment first looks for the canonical URL. If the canonical URL is not provided, Segment uses
location.hreffrom the DOM API.
- id stringA unique identifier for a Data Pipelines event, ensuring that each individual event is unique.
- received_at string (date-time)The ISO-8601 timestamp when Data Pipelines receives an event.
- sent_at string (date-time)The ISO-8601 timestamp when a library sends an event to Data Pipelines.
-
- createdAt string (date-time)We recommend that you pass date-time values as ISO 8601 date-time strings. We convert this value to fit destinations where appropriate.
- email stringA person’s email address. In some cases, you can pass an empty
userIdand we’ll use this value to identify a person. - Additional Traits* any typeTraits that you want to set on a person. These can take any JSON shape.
- user_id stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Groups files contain group calls made from your sources. If your integration outputs CSV or parquet files, the context and traits columns contain stringified objects.
- anonymous_id stringA unique substitute for a User ID in cases when you don’t have an absolutely unique identifier. Our libraries generate this value automatically to help you track people before they sign up, log in, provide their email, etc.
- group_id stringID of the group
- id stringA unique identifier for a Data Pipelines event, ensuring that each individual event is unique.
- objectTypeId string
If you use Customer.io Journeys as a destination, this value is the type of group/object your group belongs to; object type IDs are stringified integers. If you don’t include this value, we assume the object type ID is
1. See objects in Customer.io Journeys for more information.You can include this value as
objectTypeIdat the top level of your payload or asobject_type_idin thetraitsobject. - received_at string (date-time)The ISO-8601 timestamp when Data Pipelines receives an event.
- sent_at string (date-time)The ISO-8601 timestamp when a library sends an event to Data Pipelines.
-
- Additional Traits* any typeTraits can have any name, like `account_name` or `total_employees`. These can take any JSON shape.
- user_id stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Tracks contains entries for the track calls you send to Customer.io. It shows information about the events your users perform.
If your integration outputs CSV or parquet files, the context and properties columns contain stringified objects. If your integration outputs JSON files, the context and properties columns contain objects.
- anonymous_id stringA unique substitute for a User ID in cases when you don’t have an absolutely unique identifier. Our libraries generate this value automatically to help you track people before they sign up, log in, provide their email, etc.
- contextA dictionary of context about a source call/event, like the user’s IP address or locale. Context is automatically collected by our source libraries.
- active boolean
Whether a user is active.
This is usually used to flag an .identify() call to just update the traits but not “last seen.”
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe local string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. Segment first looks for the canonical URL. If the canonical URL is not provided, Segment uses
location.hreffrom the DOM API.
- event stringThe slug of the event name, mapping to an event-specific table.
- event_text stringThe name of the event.
- id stringA unique identifier for a Data Pipelines event, ensuring that each individual event is unique.
-
- Event Properties* any type
- received_at string (date-time)The ISO-8601 timestamp when Data Pipelines receives an event.
- sent_at string (date-time)The ISO-8601 timestamp when a library sends an event to Data Pipelines.
- user_id stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Pages contains entries for the page calls your sources send to Customer.io. If your integration outputs CSV or parquet files, the context and properties columns contain stringified objects. If your integration outputs JSON files, the context and properties columns contain objects.
- anonymous_id stringA unique substitute for a User ID in cases when you don’t have an absolutely unique identifier. Our libraries generate this value automatically to help you track people before they sign up, log in, provide their email, etc.
- contextA dictionary of context about a source call/event, like the user’s IP address or locale. Context is automatically collected by our source libraries.
- active boolean
Whether a user is active.
This is usually used to flag an .identify() call to just update the traits but not “last seen.”
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe local string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. Segment first looks for the canonical URL. If the canonical URL is not provided, Segment uses
location.hreffrom the DOM API.
- id stringA unique identifier for a Data Pipelines event, ensuring that each individual event is unique.
-
- category stringThe category of the page. This might be useful if you have a single page routes or have a flattened URL structure.
- path stringThe path of the page. This defaults to
location.pathname, but can be overridden. - referrer stringThe referrer of the page, if applicable. This defaults to
document.referrer, but can be overridden. - search stringThe search query in the URL, if present. This defaults to
location.search, but can be overridden. - title stringThe title of the page. This defaults to
document.title, but can be overridden. - url stringThe URL of the page. This defaults to a canonical url if available, and falls back to
document.location.href. - Page Properties* any type
- received_at string (date-time)The ISO-8601 timestamp when Data Pipelines receives an event.
- sent_at string (date-time)The ISO-8601 timestamp when a library sends an event to Data Pipelines.
- user_id stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Screens files contain entries for the screen calls your sources send to Customer.io. If your integration outputs CSV or parquet files, the context and properties columns contain stringified objects. If your integration outputs JSON files, the context and properties columns contain objects.
- anonymous_id stringA unique substitute for a User ID in cases when you don’t have an absolutely unique identifier. Our libraries generate this value automatically to help you track people before they sign up, log in, provide their email, etc.
- contextA dictionary of context about a source call/event, like the user’s IP address or locale. Context is automatically collected by our source libraries.
- active boolean
Whether a user is active.
This is usually used to flag an .identify() call to just update the traits but not “last seen.”
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe local string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. Segment first looks for the canonical URL. If the canonical URL is not provided, Segment uses
location.hreffrom the DOM API.
- id stringA unique identifier for a Data Pipelines event, ensuring that each individual event is unique.
-
- Additional event properties* any typeProperties that you sent in the event. These can take any JSON shape.
- received_at string (date-time)The ISO-8601 timestamp when Data Pipelines receives an event.
- sent_at string (date-time)The ISO-8601 timestamp when a library sends an event to Data Pipelines.
- user_id stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
The Alias schema contains entries for the alias calls you send to Customer.io. It shows information about the users you merge, with each entry showing a user’s new user_id and their previous_id.
- id stringA unique identifier for a Data Pipelines event, ensuring that each individual event is unique.
- previous_id stringThe userId that you want to merge into the canonical profile.
- received_at string (date-time)The ISO-8601 timestamp when Data Pipelines receives an event.
- sent_at string (date-time)The ISO-8601 timestamp when a library sends an event to Data Pipelines.
- user_id stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.

